Microsoft recently released data sets of roads it detected via machine learning globally.
Each file they released was quite large ( the Middle East file is a bit more than 3GB) and in a text format which most Geospatial software don’t read out of the box (as is, each row has its own GeoJSON in the geometry row).
Since the release I saw a lot of points explaining how it can be parsed into a standard geospatial format using R or Python or any other method, they looked very impressive.
I did not however see anyone just use GDAL to parse the data,
which I figured should be pretty simple and probably require just one command of ogr2ogr.
Last week I finally got around to testing it and finding the correct way to do it.
It wasn’t as simple as I thought, but using a bit of SQL it works like a charm.
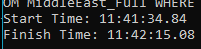
Using the following command, I selected all the road for Israel from the Middle East file and converted it to GeoPackage. The program ran for a bit less than 2 minutes with GDAL 3.1 (so not even the latest version was needed).
ogr2ogr OUTPUT.gpkg MiddleEast_Full.tsv -oo HEADERS=NO -f "GPKG" -dialect sqlite -sql "SELECT field_1, SetSRID(GeomFromGeoJSON(REPLACE(REPLACE(REPLACE(REPLACE(substr(field_2,24),',properties:{}}',''),'type','"""type"""'),'LineString','"""LineString"""'),'coordinates','"""coordinates"""')),4326) geom FROM MiddleEast_Full WHERE field_1 = 'ISR'"
Broken down, it’s relatively simple, with the SQL a bit long.
So let’s break it down:
ogr2ogr- the command we want to run, you can find its full documentation here, but some options that it can handle relate to the input (open options) or to the output (layer creation options “lco”)OUTPUT.gpkg MiddleEast_Full.tsv- the output file followed by the input file (that’s the order GDAL takes them 🤷)-oo HEADERS=NO--oostands for open options, i.e. options on how to read the file,HEADERS=NOmeans that the file has no headers in the first row and that there are no field names so we will use field_1, field_2…field_n in the SQL.-f "GPKG"- Just making sure GDAL understands what I want as my output format, otherwise it is derived from the output file name.-dialect sqlite- What SQL dialect should GDAL use, this is important because we need theGeomFromGeoJSONfunction which theOGRSQLdialect doesn’t have (this saves us using another function).-sql "the query"- Use the following SQL query on the input data and get the output of the query as the final product. If you just want to filter by a column, you can use the-whereoption instead or the-spator any of the-clip*options for spatial filtering.
Now let’s break down the SQL query itself.
An input row looks like this:
IRQ {"type":"Feature","geometry":{"type":"LineString","coordinates":[[44.8856135,31.9661057],[44.886382,31.96527]]},"properties":{}}
It is Tab separated, which is something GDAL could handle directly with the CSV vector driver but… when GDAL reads the second column, which houses the geometry, it removes the quotation marks and makes the GeoJSON invalid when it reads it, GDAL also expects GeoJSON geometries as just the geometry part, without the properties, or the “type”:”Feature” part.
The full query looks like this:
SELECT
field_1, -- the country code field
SetSRID(
GeomFromGeoJSON(
REPLACE(
REPLACE(
REPLACE(
REPLACE(
substr(field_2,24)
,',properties:{}}','')
,'type','"""type"""')
,'LineString','"""LineString"""')
,'coordinates','"""coordinates"""')
)
,4326) geom
FROM MiddleEast_Full
WHERE field_1 = 'ISR'
The SELECT starts with field_1, which grabs the first column, if you want just the geometry (for everything) you can drop that, now let’s break down the functions that help us grab the second (geometry) column, from the inside out:
-
I start with
substr(field_2,24)which gets everything after the 24th place in the string (the column is just plain text, so we treat it like a string for now), meaning, everything after ’{“type”:”Feature”,”geometry”:’. -
Replace ‘,properties:{}}’ with nothing, i.e. remove the last part of the string.
-
Replace
'type'with'"""type"""', i.e. add quotation marks.
why do I need 3 pairs? 🤷 no Idea, but it works, I got to it after trying regular SQL which didn’t work, but then tried running it through QGIS (on the smaller version of the file) and got this version that works. -
& 5. Do the same as 3 for the other 2 strings (‘LineString’ and ‘coordinates’).
We should now have the geometry part of a GeoJSON which GDAL will recognize.
-
Wrap all of that up in
GeoFromGeoJSONwhich will make GDAL understand our string as a geometry it can then convert to any format. -
Define the geometry CRS with
SetSRID(geometry object,4326)(GeoJSON should always according to the spec be in WGS84 which has the EPSG code of 4326).
The geom after all of that is for setting the column name, otherwise the column name will be the full functions which is less than ideal.
The FROM part expects the name of the input file, without the extension type.
The WHERE part is simple SQL in this case, just grabbing Israel by using the first field with the ‘ISR’ country code.
Using this command, on the MiddleEast_Full.tsv file (3.7GB, 17,599,110 rows) it took less than a minute to get the output GeoPackage which is only 53.4MB with 319,083 features.
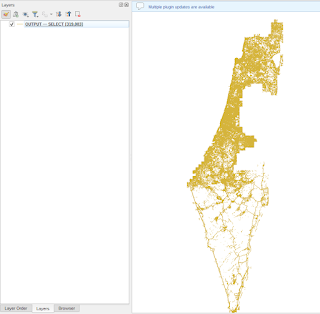
And that’s it, everything you need to convert the MicroSoft *.tsv file into a workable GeoPackage or just any other format, since you can just change the output type.
I also tried this with GeoParquet and just plain CSV, but GeoPackage was the fastest one.
UPDATE
I was asked if this could be duplicated for the Microsoft detected buildings layer, that is documented here.
It is actually a bit easier, for several reasons:
-
The buildings layer is split into multiple small files.
-
You can find the links for all the small files for a country, using the datasets-links.csv.
-
Microsoft already provided a python script that helps grab one country and converts each file to a GeoJSON file.
-
The files are Technically not GeoJSON, but GeoJSONL which means every feature is in a new line, if you change the extension name of each file, you can just drag & drop it into QGIS.
What steps I found easiest to convert them all to one layer:
- Download all the files for the country you want to grab - can be done manually if there aren’t a lot of files or using a simple download script.
I used this variation on the script Microsoft supplied:
import os
import gzip
import pandas as pd
import urllib.request
"""
Will read and unpack all the files for one country,
change location to official name of another country
"""
def main():
# this is the name of the geography you want to retrieve. update to meet your needs
location = 'Israel'
dataset_links = pd.read_csv("https://minedbuildings.blob.core.windows.net/global-buildings/dataset-links.csv")
links = dataset_links[dataset_links.Location == location]
for _, row in links.iterrows():
dirname = os.path.dirname(__file__)
out_path = os.path.join(dirname, "geojson","{}.geojsonl".format(row.QuadKey))
download_file(row.Url,out_path)
def download_file(url,out_file):
# Download archive
try:
# Read the file inside the .gz archive located at url
with urllib.request.urlopen(url) as response:
with gzip.GzipFile(fileobj=response) as uncompressed:
file_content = uncompressed.read()
# write to file in binary mode 'wb'
with open(out_file, 'wb') as f:
f.write(file_content)
return 0
except Exception as e:
print(e)
return 1
if __name__ == "__main__":
main()
Each of these files can be just drag and dropped into QGIS, this is pretty easy to perform even for weaker computers as the largest file for Israel was a bit more than 140MB.
After you have the files you can just go ahead and convert them to GPKG with one command, unfortunately, you can just use ogr2ogr output.gpkg *.geojsonl, but you can use an iterator to do that for every file and append them all to the same table.
This is the command I use in Windows command line (CMD):
for %f in (*.geojsonl) do ogr2ogr -f "GPKG" buildings.gpkg %f -append -update -nln israel_buildings
It took a couple of seconds and the created GeoPackage was about 300MB from around 460MB of GeoJSONL files.